Nowadays, business have a great demand for the best free OCR tools, as you more or less need to extract text from image or scanned documents.
However, building an OCR solution from scratch is impractical. You need a huge dataset for training and refining. In most cases, tweaking open source OCR tools should suit your needs.
If you want to get an excellent open source OCR software, you can find the best one in this post. We will compare and discuss the advantages and limitations of each open source OCR tools based on factors such as accuracy, OCR performance, language support, usage cost, customization options, and community support. I also include a brief comparison table to make it easier for you to choose the open source OCR tool for your projects.

| How many tools we tested | 14 open-source programs |
|---|---|
| What devices we tested | On a Dell PC and an iMac |
| Total testing time | 2 weeks |
| What we OCRed | invoices, receipt, contract, scanned PDF, screenshots, brochures, handwritings, etc. |
| How we evaluate the result | OCR performance, language support, usage cost, customization options, and community support. |
Compared with open source OCR tools, Pre-trained models offer convenience and ease of use, and is a very good option for people who have no code skill and have limit resources and expertise to develop and maintain open source OCR tools.
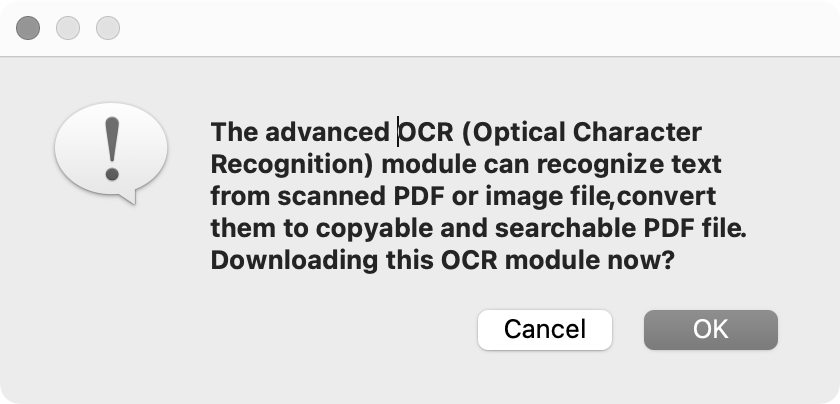
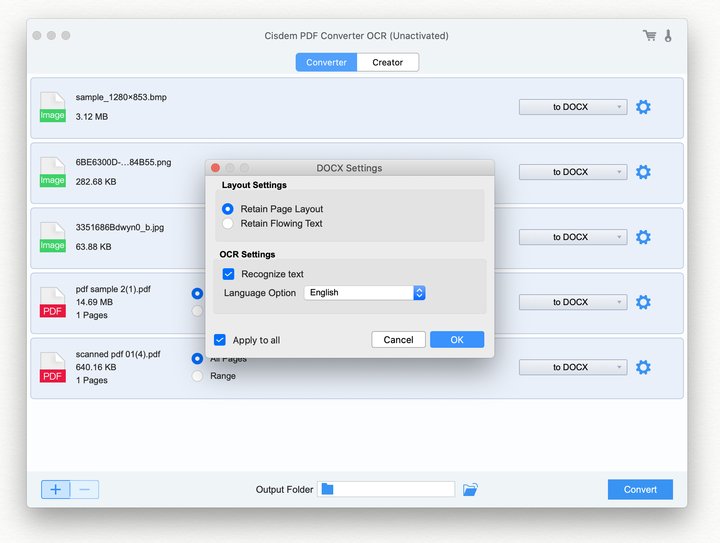
Cisdem PDF Converter OCR is a fantastic OCR program that is widely used by all levels of users. It is compatible with both Windows and macOS computers. As a specialized PDF converter, it supports various file inputs and outputs. You can convert scanned PDFs and images to editable Word, Excel, PowerPoint, Pages, Keynotes and so forth. Plus, it also lets you turn multiple different files back into PDF, even merge them. All these types of conversion enable bulk processing and multi-language recognition.
If you're hesitant to pay for it, it offers a generous trial period, so you can download and try how it performs. Although it’s not an open source OCR tool, it can surely meet all your requirements.
 Free Download Windows 11/10/8/7
Free Download Windows 11/10/8/7  Free Download macOS 10.13 or later
Free Download macOS 10.13 or later
By Resolution
OCR result are highly related with input image quality, in our test we input images in different resolution to the program (100DPI/150DPI/300DPI/600DPI) and the performance are as follows.
| Resolution | Recognition rate | Number of characters correctly recognized |
|---|---|---|
| 600DPI | 98.73% | 1044 characters / 1057 characters |
| 300DPI | 99.92% | 1053 characters / 1057 characters |
| 150DPI | 91.53% | 970 characters / 1057 characters |
| 100DPI | 82.83% | 860 characters / 1057 characters |
See, it shows a high recognition rate even at a resolution of around 150DPI and all text read satisfactorily.
By font size
Font size is another factor that can greatly impact OCR recognition accuracy.
| Paper size | Recognition rate | Number of characters correctly recognized |
|---|---|---|
| Same size | 99.04% | 1039 characters / 1057 characters |
| 1/2 times | 99.42% | 1051 characters / 1057 characters |
| 1/4 times | 99.32% | 1050 characters / 1057 characters |
| 1/6 times | 85.98% | 933 characters / 1057 characters |
| 1/9 times | 86.56% | 939 characters / 1057 characters |
See, even documents reduced to 1/4 times can be read satisfactorily.
Free Download Windows 11/10/8/7 Free Download macOS 10.13 or later
To check out the reasons that we recommend Cisdem PDF Converter OCR, check our comparison table below:
| Method | Precision(%) | Processing time | Beginner-friendliness | OCR performance | Usage cost |
|---|---|---|---|---|---|
| Cisdem | 99.94 | 0.73s | ★★★★★ | ★★★★☆ | ★★★★★ |
| Tesseract | 98.9 | 0.85s | ★★★★☆ | ★★★☆☆ | ★★★★☆ |
| EasyOCR | 88.15 | 3.90s | ★★★☆☆ | ★★★★★ | ★★★★☆ |
| PaddleOCR | 91.96 | 1.52s | ★★★☆☆ | ★★★★☆ | ★★★☆☆ |
| Kraken | 83.68 | 2.48s | ★★★☆☆ | ★★★☆☆ | ★★★☆☆ |
| GOCR | 79.83 | 5.47s | ★★★★☆ | ★★☆☆☆ |
★★☆☆☆ |
https://github.com/tesseract-ocr/tesseract
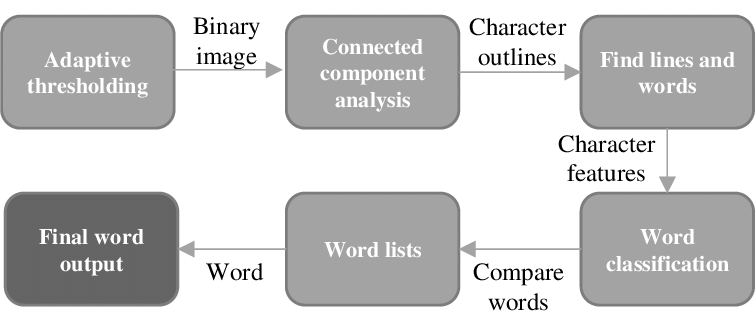
Tesseract is one of the most well known OCR open-source engines which initially developed by Hewlett-Packard and now maintained by Google since 2006. It is Known for its accuracy and provides customization and functionality for further development. With its LSTM based latest stable 4.1. 1 version, Tesseract now covers up to 116 languages.
Tesseract was developed in C++ and has wrappers available for Python, Java, Swift, Ruby, etc. Tesseract’s OCR engine uses the "Leptonica library", it supports opening images in TIFF, PNG, and JPG format, and can output files in PDF, HTML, TSV, or plain text. At the time of writing, Tesseract’s main repository has 43.8k+ stars and 7.8k+ forks.
Beginner-friendliness (★★★★☆)
It have many documentation on the official website, you can start with the Beginner’s Guide an choose the guide from 4 categories which has dedicated documentation link for users with different needs.
OCR performance (★★★☆☆)
In our test, we find that the accuracy of Tesseract output depends on various factors, like language, image quality, data size, pre-trained data, etc. It delivers high OCR accuracy for machine-printed text, but for other type of files, you need to manual training and tuning for specific use cases. And, it have some problem at recognizing handwriting and low-quality scans.
Tesseract delivers impressive OCR accuracy, particularly for machine-printed text and well-scanned documents, making it suitable for various applications.
Usage cost (★★★★☆)
It has a complex authentication process, but the overall experience is not bad. The development time cost is relatively low—you can simply tweak the demo code.
Real-world applications
Tesseract is widely used in the fields of image recognition and digitalizing documents.
git clone https://github.com/tesseract-ocr/tesseract.git
cd tesseract
./autogen.sh
./configure
make
sudomake install
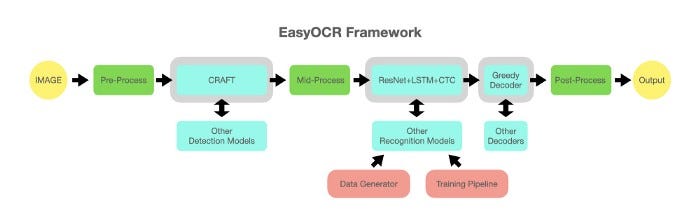
EasyOCR is an open-source and ready-to-use OCR with almost 80+ language supports. It is developed by Jaded AI, and built on top of the PyTorch library. You can choose to train the model with your own data or just use the existing models.
EasyOCR uses machine learning (CRNN) for OCR. You can check the demo on on Huggingface.
It is written in Python and supports only the Python programming language. Also, it does not provide as many customization options as Tesseract.
Beginner-friendliness(★★★☆☆)
At this point, development is very active and always in time at responding to issues/questions. The documentation on GitHub might be a bit challenging for non-technicals, but it’s quite clear for developers.
OCR Performance (★★★★★)
EasyOCR is OCR engine that developed relatively recently. It is known for its ease of use and accuracy. In our test it gives the most accurate result, although some small characters are mis-recognized. In some cases it can even recognize texts in handwriting.
Usage Cost (★★★★☆)
For EasyOCR, installation is convenient, no registration or authentication required and it can be done directly with pip.
Real-world applications
Suited for OCR applications with high requirements for text layout and character detection accuracy, such as business card recognition, invoice recognition, and product label recognition.
import easyocr
reader = easyocr.Reader([‘en’, ‘ch’])
img_path = ‘/path/to/image.png’
img = easyocr.imgproc.read(img_path)
result = reader.readtext(img)
for line in result:print(line)
https://github.com/PaddlePaddle/PaddleOCR
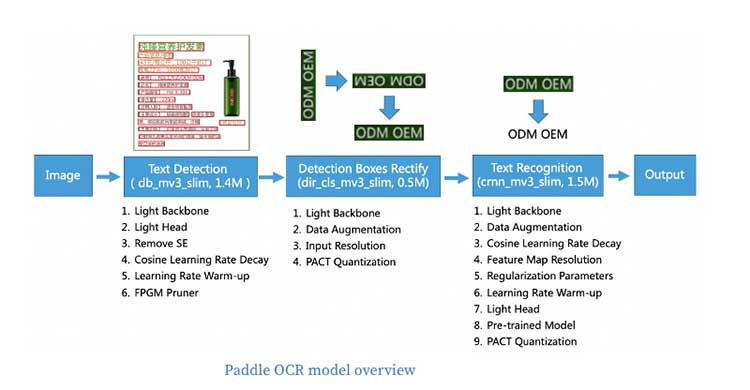
This is a simple but high-precision text recognition model developed by Baidu Research. It is based on the deep learning framework Paddle(PArallel Distributed Deep LEarning).
The latest version of PaddleOCR uses PGNet, and trained on enormous English and Chinese data base. Compared with other open source OCR tool it is really lightweight - less than 10MB in size and the speed is very quick.
It support 80+ languages and have very good performance in languages like English, Chinese, French, German, Arabic, etc. It provides OCR algorithms in text detection models or text recognition models.
PaddleOCR supports the Python programming language, but you can also use C++
Beginner-friendliness (★★★☆☆)
Detailed documentation on usage which covers OCR definitions, scenarios, dataset loading, model loading, prediction, deployment, and instance demos in a straightforward manner.
OCR Performance (★★★★☆)
In our test, PaddleOCR isn’t necessarily the most accurate, but after training, it have almost the same result as Tesseract, especially in the Asia languages. It can properly detect language in English and specially good at recognizing Chinese, but it do have problem dealing special characters, periods and commas.
Usage Cost (★★★☆☆)
Very easy to utilize and I experimented with web, API OCR, and all were accomplished within a few minutes. So, virtually no usage cost.
Real-world applications
It is suitable for OCR recognition in scenarios like ID cards, invoice, bank cards, license plates, etc.
import paddleocr
ocr = paddleocr.OCR()
img_path = ‘/path/to/image.png’
img = paddleocr.read_image(img_path)
result = ocr.ocr(img)
for line in result:
print(line)
https://github.com/mittagessen/kraken
Kraken is an Python developed open source OCR engine that performs really good at non-Latin characters. Kraken uses deep learning algorithms and performs really good at various fonts and layout styles. It supports languages that are written from right to left, such as Arabic, and languages that are written from top to bottom, such as Japanese.
Compared with other open source OCR tools, it’s language support is rather limited, currently it only supports a few languages including English, French, and German. And it’s community is not large at the moment, so you will need to debug and testing to solve issues you met.
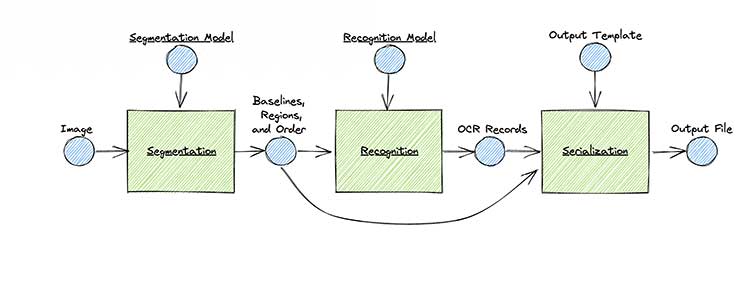
Its features include:
GOCR is an open-source OCR engine developed under the GNU General Public License. It is mainly used for text recognition in images. It employs deep learning models and computer vision techniques, enabling accurate text recognition in various scenarios.
It comes with two recognition methods, you just need to choose one based on your needs:
General Method: Recognize all text in an image.
Char Method: Recognize each individual character in an image.
For language support, it currently supports: German, Spanish, French, Polish, Portuguese, Ukrainian, English, Japanese, Simplified Chinese
While its accuracy may not surpass other open source OCR engines, it is simple and ease to use and offers a user-friendly interface.
Its features include:
On this page, we shared with you the top 6 best open source OCR tools. Whether you are working on a Windows, macOS, or Linux computer, you can always find the best one that suites your needs here.
Also, noted that the OCR tools we recommend above all have active development communities on Github, you can ask questions and learn from there.
Though, ideally we’d like to find tools that would be a solid five stars in all categories, but you can see none of these tools quite hit the mark.
If you know code you just need to choose one of the open source engine above, but if you are a user with basic OCR needs, Cisdem PDF Converter OCR is your best option. Although it’s not open source, it can satisfy almost all of your needs. Try it now!
License: Apache License 2.0
Supported Languages (pre-trained): 100(+)
URL: https://github.com/tesseract-ocr/tesseract
License: Apache License 2.0
Supported Languages (pre-trained): 80(+)
URL: https://github.com/JaidedAI/EasyOCR
License: Apache License 2.0
Supported Languages (pre-trained): 80(+)
URL: https://github.com/PaddlePaddle/PaddleOCR
License: Apache License 2.0
Supported Languages (pre-trained): 3(+)
URL: https://github.com/mittagessen/kraken
License: Apache License 0.52
Supported Languages (pre-trained): 10(+)
URL: https://github.com/SureChEMBL/gocr

Rosa has worked in Mac software industry for more than eight years. She believes that the purpose of software is to make life better and work more productively. In addition to writing, Rosa is also an avid runner.




